Enhanced Curiosity to explore 3D Worlds
Reinforcement Learning algorithms train an agent from the reward signal it obtains. Thus, a naïve agent relies on exploration to collect its first rewards. Random actions can proved to be efficient in some setting, like illustrated in Maze DQN . But, in environments where rewards are sparse, this exploration can prove to be overly long and hazardous. This is where curiosity comes at the rescue !
How can we make the most of curiosity to explore reward-sparse environments ?

1. Curiosity Formalism
The whole idea of curiosity is to guide the agent throughout its exploration by adding an extra reward. This is called intrinsic motivation because it is computed by the agent itself rather than by the environment. The formalism used here is the one introduced in Curiosity-driven Exploration by Self-supervised Prediction (2017). They obtain impressive results by playing Mario with no reward, implying that the agent can learn from pure curiosity. They introduce the Intrinsic Curiosity Module (ICM) that computes the curiosity reward from a current state, the action taken by the agent and the subsequent state.
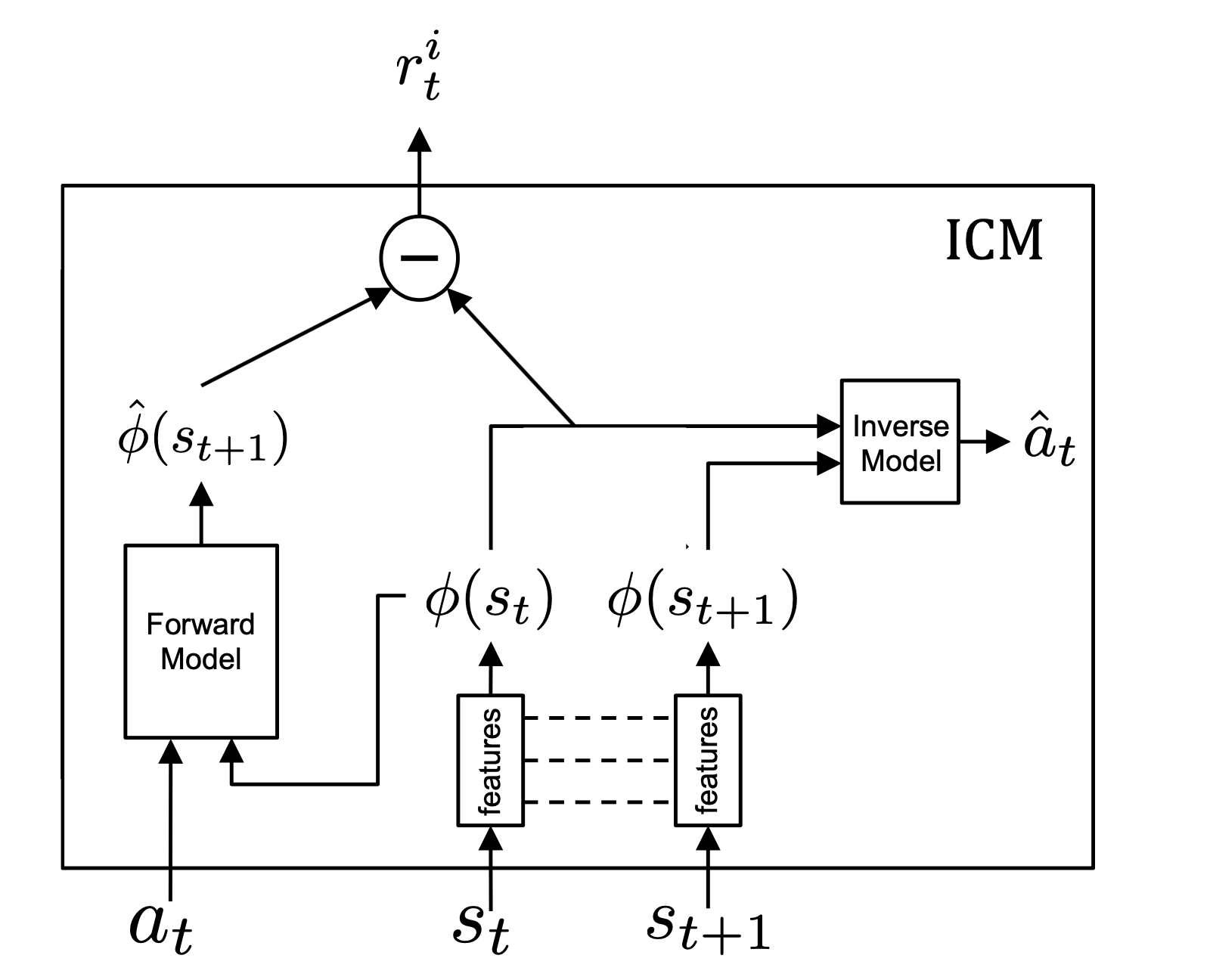
Curiosity is computed by a neural network that takes as input the action and an encoding of the current state and predicts the encoding of the next state. The L2 norm of the supervised loss between that prediction and the true encoding is what we call the curiosity reward :
$$ r_i = ||F(\phi(s_t), a_t) - \phi(s_{t+1})||_{L^2} $$
2. Curiosity Relies on Image Encoding
A curiosity survey paper points out that the state observation should be encoded in a compact vector. In the ICM module, the encoding is computed by an Inverse Model that tries to predict what action where chosen given the encodings of two subsequent states, denoted as Inverse Dynamics-Features (IDF). Nonetheless, the survey paper concludes from experiences on the Atari benchmark that random feature (RF) encodings are actually pretty good because, while not sufficient, are stable and that’s really important for the curiosity signal. Does that claim still holds when we train agents in complex 3D environments ?
3. The Animal AI Testbed : Detour Tasks
The perfect benchmark for the experiment is the Detour Task enviroments of the AnimalAI testbed. Detour tasks are simple cognitive tasks but hard for AI. They require moving away from a reward in order to get to it, which is impossible with a naive ‘go towards good thing’ strategy. The top 10 teams in Animal-AI Olympics averaged only 12% success in the AnimalAI Olympics . They might not be the only one having a hard time on the Cylinder Task:

On these tasks, Random Feature Curiosity might prove to be insufficient. Indeed, nothing prepares it to recognize 3D structures, to be invariant to brightness and transparency for example.
4. Enhanced State representation for optimal curious exploration
- Describe VAE method !
Our results show a great sample efficiency gain of VAE based curiosity compared to the two baselines IDF and RF when learning over a curriculum of increasingly complex tasks.
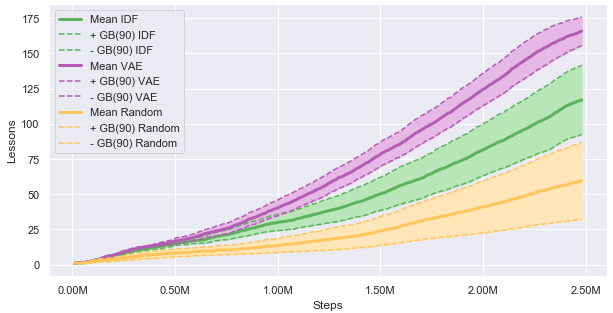
Besides, improving significantly the sample-efficiency of the training, the resulting agent performs better when evaluated on other X-Maze tasks that it as never seen:
5. Transfer to other Detour Environments
We also found zero-shot transfer to other detour tasks is much better with the more structured encoding (VAE than IDF or RF). Our agent is able to succeed in the Cylinder task without being trained on it !